Read up on our collection and analysis methods from our featured snippet whitepaper.
Hold on to your hats, SEO nerds: it’s about to rain data up in here.
As you may know, we recently dove head-first into the world of featured snippets in our whitepaper, Rise to the top with featured snippets, to see if we could unlock their mysterious inner-workings. In order to perform a rigorous analysis on this universal result type, we tackled an Everest-sized mountain of data.
THE DATA
We packaged up the core STAT ranking data for one million high-CPC queries, the list of queries that returned a featured snippet, and a list showing how often each word in a query returned a featured snippet.
- Query ranking data
This was the full list of one million keywords and the top 10 SERP results for each. The file contained close to 10 million rows. - Featured snippet queries
This was the full list of queries (92,832) that generated a featured snippet. - Word frequency list
And this file contained the full list of individual words (8,470) within our keyword set that occurred more than 25 times and the frequency with which they generated a featured snippet.
While STAT tracks desktop and mobile SERPs in different languages all over the world, in order for us to keep the scope of our research manageable, we narrowed our focus to only desktop results from the US, English market.
HOW WE COLLECTED THE DATA
To gather the sheer amount of data we would need for this analysis — one million SERPs — we went straight to STAT. Once we had that SERP data in hand, we supplemented it with a number of on-page and off-site metrics to round out our analysis.
STEP 1: Gather core keyword & ranking data
First, we got to work selecting our keyword set. We decided to use the one million highest-CPC keywords in the GrepWords database, released in January 2015 by Russ Jones of Moz and GrepWords.
We then loaded those keywords into STAT to collect ranking data (gathered on January 16 and 17, 2016). A final list of 999,868 keywords was used in our research; approximately 132 keywords were perfect duplicates or returned invalid search results, and therefore didn’t make the cut.
Step 2: Look at the entire SERP
In order to get our hands on the most SERP detail possible, we also used STAT’s optional bulk HTML API to generate HTML snapshots of the 100-result SERPs for each keyword.
Those HTML SERPs were then put through Outwit. With each feature of interest, we used markers comprised of HTML and CSS code coupled with regular expressions before and after.
We looked for various types of SERP features such as knowledge graphs results, “People also ask” questions, and “Shop for on Google” ads.

SERP feature markers
Here’s a list of the SERP features we parsed and associated markers.
Step 3: Dig deeper into on-page & off-site data
If the above data wasn’t enough already, we went looking for even more.
Our next step was to create a list of the top 10 unique URLs for queries that returned a featured snippet: 346,643 URLs in total. (There were a substantial amount of duplicate URLs just due to the nature of our keyword list.)

URL profiler
We used these settings during the URL Profiler data pull.
With this list, we gathered supplemental on-page and off-site metrics for each URL by using a combination of URL Profiler and Screaming Frog. We used custom search in Screaming Frog to help identify the presence of tables, lists (ordered and unordered), and Schema.org markup.
We reviewed the average values for URLs that returned featured snippets and compared them to non-snippet results from the same SERPs for the following factors:
i. Off-site metrics
- Moz Page Authority
- Moz root domains linking to page
- Moz domain authority
- Moz root domains linking to domain
- Social shares: Facebook, LinkedIn, and Pinterest
ii. On-page content metrics
- Flesch-Kincaid readability
- Word count (URL Profiler)
- Presence of
<ol>or<ul>lists - Presence of
<table> - Presence of search query in
<title>tag - Presence of search query in
<H1>
iii. Technical SEO
- Presence of schema.org code snippets
- Response time and page speed
WHAT WE LOOKED AT IN OUR ANALYSIS
We put on our smocks and safety googles and got to work in Excel and Tableau, looking at all the factors that contribute to winning a featured snippet.
With almost 100 million rows of data in the complete rankings file, tools like Tableau were essential in handling files that Excel could not process.
1. Co-occurrence with other result types
We used Tableau to determine the co-occurrence of featured snippets with various SERP features and result types. The universal result types we focused on include:
- Places
- Knowledge graph: “People also ask”
- Knowledge graph: “See results about”
- Videos
- Images
- News
- Shopping
- Twitter box
- Flights
- App downloads
2. Featured snippets vs. CPC, search volume, & query length
When looking into how CPC, search volume, word count, and query length affect featured snippet generation, we decided against doing correlation studies as the outcome was binary — a featured snippet either appeared or it didn’t.
Instead, we bucketed the various factors into 10 percentile groups, each representing 10 percent of the data. This also allowed us to easily chart the results instead of cramming one million data points into a single graph.
3. Featured snippets vs. on-page & off-site metrics
For on-page and off-site metrics, the data we generated from URL Profiler and Screaming Frog resulted in just over 4,853,000 data points, which were then combined with SERP data in Excel and tested against the presence (or lack) of featured snippets.
During this round of edits, we removed any URLs that generated invalid data. Invalid data could include 400 or 500 level server response codes, more than 2-3 levels of redirects between the indexed URL and the final destination URL, and results with null data in all rows.
After tarting up the data, all on-page and off-site frequency calculations were performed on samples between 500,000 and 700,000 rows of data.
4. Word frequency in featured snippet queries
In order to determine how frequently a word generated a featured snippet, we first had to count the occurrence of each word in our full data set.
For example, the three queries of [age for lasik], [seattle lasik surgery], and [lasik surgery cost] had the following occurrences:
- lasik: 3
- surgery: 2
- age: 1
- for: 1
- seattle: 1
- cost: 1
We then conducted the same process on our smaller list of 92,832 featured snippet queries and, finally, filtered out words that occurred less than 25 times to focus on only the most common.
With those two sets of occurrence rates (full data set and featured snippet set), we were able to calculate a featured snippet frequency percentage for every word on our list. Whew!
Running with our previous example, if [age for lasik] and [lasik surgery cost] produced featured snippets, but [seattle lasik surgery] did not, we’d calculate a featured snippet frequency like this:
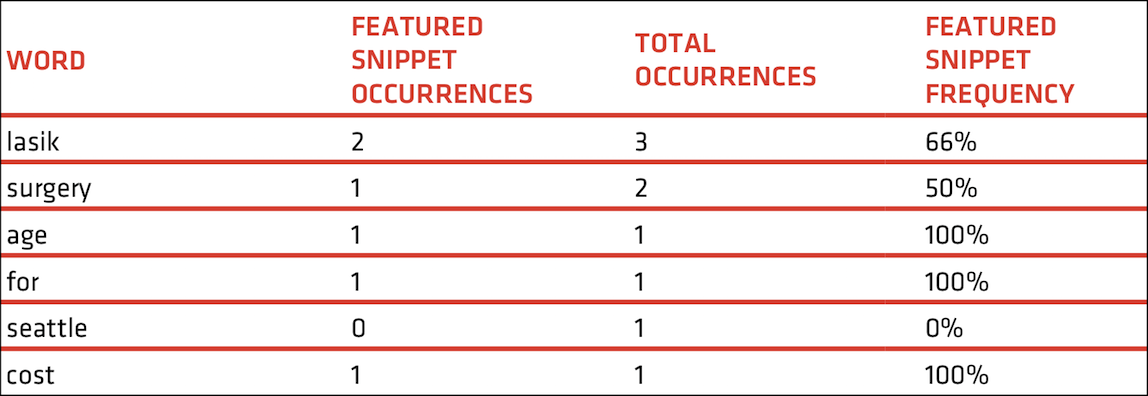
Feature snippet word frequency
Here’s how we calculated word frequencies for featured snippet results.
This resulted in a list of 8,470 words that generated a featured snippet. In the whitepaper, we actually filtered down one more time to words with greater than 100 occurrences to look at overarching query themes.
For ease of comparison, the top 100-200 words and the bottom 100-200 words were grouped by topic in order to view trends. We ended up with 16 topics covering both ends of the spectrum of featured snippet frequency.
WHO WE’D LIKE TO THANK
First off, big thanks to Russ Jones of Moz and Grepwords for releasing the list of the top one million high-CPC keywords in the Grepwords database along with CPC and volume information. (Our data set excluded the CPC and search volume info.)
Secondly, thank you to Pete Meyers, (yes again), AJ Kohn, Dan Shure, and Geoff Kenyon for contributing their thoughts to our study. We reached out to each of them via email to see what questions they had about featured snippets and answer boxes so we could integrate them into our research.
MORE FEATURED SNIPPET INSIGHTS
For an in-depth look at high-CPC SERPs, million-dollar snippets, what types of queries trigger featured snippets, and who’s winning with featured snippets, check our the full featured snippets series:
- Whitepaper: How to get more featured snippets
- Featured snippet research methodology & open-source data
- The best words and themes to generate featured snippets
- The most valuable featured snippets
- Which sites win the most featured snippets?
- Bonus SEO insights from our featured snippet research


